
Others dabble.
We deliver.
AI scaling is a coordination problem, not a computation problem. Most organizations add AI tools and see tasks move faster. But still, delivery doesn’t.
The missing layer is a shared context engine — architecture knowledge, dependency maps, and governance rules structured so parallel execution can happen without drift.
With the addition of our AI-native OS, our senior engineers become force multipliers - building on their experience to architect and build better.


A methodology-forward OS built around senior talent and supported by contextual AI
AI-native delivery is not automation replacing people. It is expert-led parallel delivery.
By decomposing work into independent threads, advancing them simultaneously, and maintaining alignment through shared context and guardrails, senior engineers scale their impact instead of becoming throughput constraints. This is what turns AI experimentation into measurable enterprise ROI.
AI can accelerate tasks.
But tools alone don’t improve delivery outcomes.
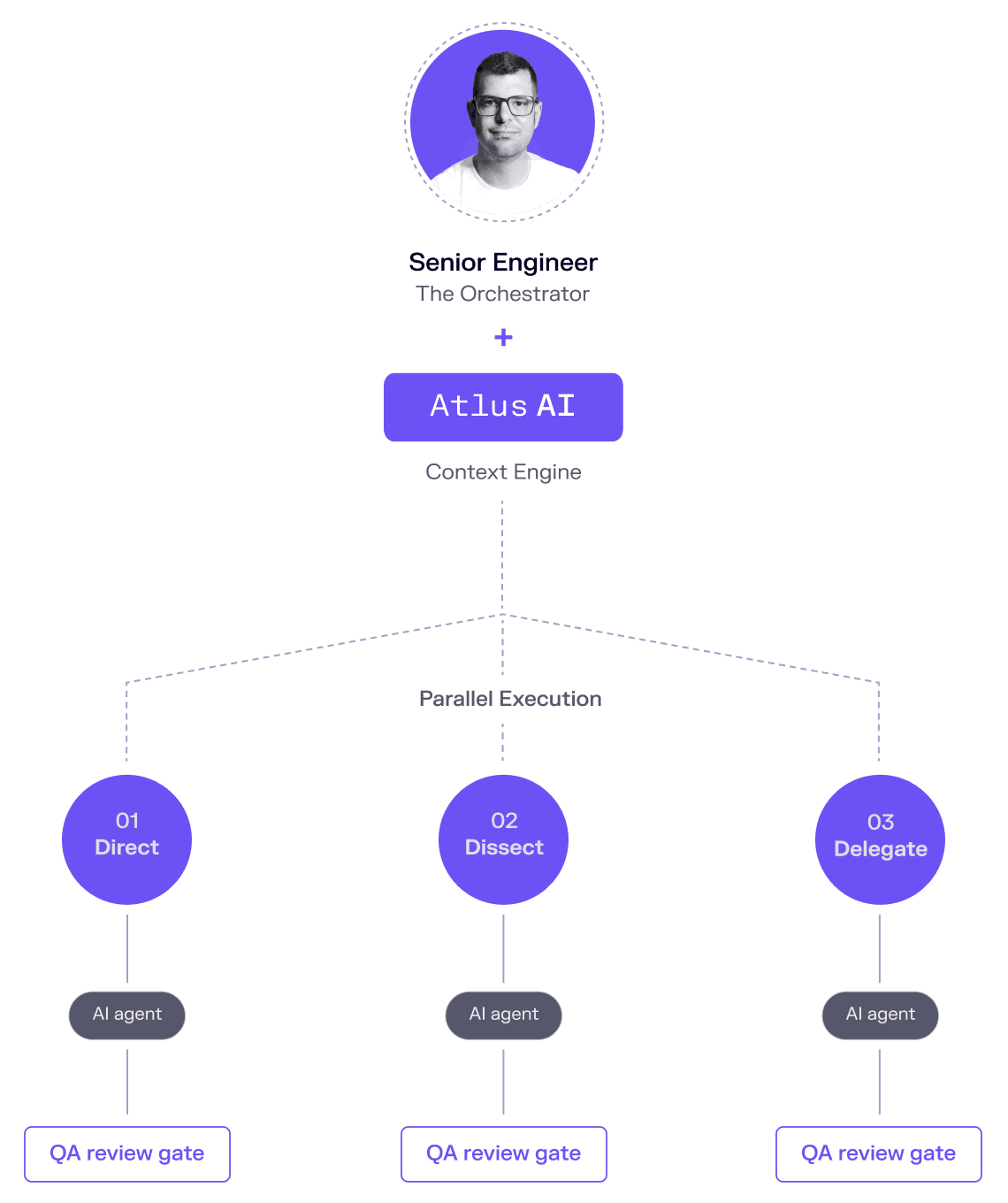
Direct
Define intent, architecture constraints, and governance rules in the shared context engine. This is what gives AI the structured input it needs to operate reliably.
Dissect
Decompose work into independent, parallelizable threads. Tasks that would execute sequentially in a traditional sprint run simultaneously under shared context.
Delegate
AI agents execute workstreams. Senior engineers orchestrate, validate, and course-correct — acting as force multipliers, not reviewers in a queue.
The AtlusAI playbook
The context engine we built to run our own SDLC.
Parallel delivery at enterprise scale requires more
than off-the-shelf tools. It requires a system that captures decisions, intent, and execution state, so senior engineers (and the AI supporting them) can operate safely in parallel.
AtlusAI is not a product we sell — it's the operating system we built to make Lumenalta's own delivery better. It captures architecture decisions, dependency maps, and governance rules in a unified context layer, enabling parallel execution across the full SDLC without coordination drag.
Our delivery playbook combines seasoned engineering judgment with purpose-built intelligence to reduce delays and unlock parallel execution.
The reason we can advise you on AI-native delivery is that we've already built the playbook and it works.
How contextual intelligence supports agentic delivery
Agentic, parallel execution only works when all contributors (human and agent) operate with shared, continuously updated context. Without it work drifts, quality degrades, risk compounds. Context keeps parallel delivery safe, scalable, and reliable.
Shared delivery context
Unifies business goals, architectural decisions, and live execution state so parallel work stays aligned and production-ready.

AI agents under senior oversight
Enterprise-grade agents execute repeatable tasks in parallel, guided by senior engineers and governed by shared guardrails.

Decision capture and workflow automation
Key decisions, code changes, and outcomes are continuously documented — reducing knowledge loss and coordination overhead.

Built-in governance frameworks
Quality, security, and compliance controls are embedded directly into execution, so speed never compromises trust.
Our AI-native OS gives senior engineers and their AI agents the clarity required to build safely, quickly, and in parallel.
How we team
Traditional delivery is a pyramid: wide junior base, thin senior layer. Scaling output means scaling headcount.
AI changes the shape.
The model shifts toward a diamond: senior engineers at the center, AI handling low-leverage work, leaders orchestrating in parallel. Output scales without added headcount.
Lumenalta is built to operate this way.
Our AI-native OS gives senior operators the context and leverage to perform at their highest level — directing, compounding, accelerating delivery.
Born from tech, not consulting, we’ve always favored small, senior teams.
Now the system makes that model scale.
Not more people. Better leverage.
Not more people. Better leverage.

Proven impact in production
Our AI-native delivery operating system gives senior engineers clarity, continuity, and leverage so teams can move faster with confidence.
Instant
Decision traceability across code, tickets, and conversations
85%
Faster onboarding — engineers move from days to hours
75%
Less meeting and demo prep time for delivery teams
40-60%
Cycle time compression - concept to iterative value
15-25%
Faster defect detection for course correction
80-90%
Reduction in QA effort through automated workflows
15-20%
Improvement in code quality and overall output
Real outcomes. Real environments.
When delivery becomes parallel and senior engineers are given leverage, the results are visible, defensible, and board-level.

Get started

Assessment & discovery
We map your SDLC, identify parallelization opportunities, and baseline your route-to-live. Readiness gaps become the roadmap.

Parallel delivery pilot
Apply the model to a real use case. Measurable results before any full commitment.

AI-accelerated senior, delivery pods
Ongoing delivery using Lumenalta's AI-native OS playbook alongside your team.

Full modernization
End-to-end re-architecture at parallel-native speed.
Increase throughput
See where our AI-native OS can compress your route-to-live.